High-level design
The architecture separates into two distinct paths, each optimized for its unique requirements.
Read (Redirect) path: Client click --> CDN --> API Gateway --> Mapping Service --> Redis Cache --> DynamoDB. Optimized for sub-10ms latency with multiple caching layers. The CDN handles the hottest URLs at edge locations. Redis handles the warm set in the data center. DynamoDB is the durable fallback for cache misses.
Write (Shorten) path: Client request --> API Gateway --> Shortening Service --> Message Queue --> Queue Worker --> DynamoDB. Optimized for reliability and database protection. The Shortening Service generates a guaranteed-unique code from its pre-allocated ID range and enqueues the write. The message queue decouples the client response from the durable write, smoothing traffic spikes.
Components
API Gateway: TLS termination, DDoS protection, request routing, and rate limiting for write requests. All external traffic enters through the gateway, providing a single enforcement point for authentication and throttling.
Shortening Service: Generates short codes from a pre-allocated ID range, validates inputs, and enqueues write requests. Each instance owns an exclusive range of IDs, so codes are guaranteed unique at generation time. Stateless and horizontally scalable behind a load balancer.
Mapping Service: Handles redirect lookups. Checks Redis first, falls through to DynamoDB on cache miss. Also stateless. This is the most latency-sensitive component.
Message Queue (SQS or Kafka): Buffers write requests between the Shortening Service and the database. If 2,000 URL creation requests arrive in one second, the queue absorbs the spike and the Queue Worker drains them at a steady 200 per second that the database can comfortably handle.
Queue Worker: Consumes messages from the queue and writes URL mappings to DynamoDB. Since codes are generated from exclusive ID ranges, collisions cannot occur, and every write succeeds on the first attempt. Rate-limited to match database write capacity.
Redis Cache: Stores the warm set of URL mappings (recently and frequently accessed). LRU eviction policy ensures the cache holds the most useful entries. Cluster mode for horizontal scaling across multiple shards.
CDN (CloudFront): Caches redirect responses at edge locations worldwide. For a viral URL, the CDN serves millions of redirects from a nearby edge node without any request reaching the backend. This is the single most impactful component for read performance.
DynamoDB: The durable source of truth for all URL mappings. Handles cache misses from Redis, supports conditional writes for custom alias conflict detection, and provides automatic TTL-based expiration.
Short Code Generation
A short code uses Base62 encoding: the characters a-z, A-Z, and 0-9, giving 62 possible characters per position. A 7-character code provides 62 to the 7th power, which equals approximately 3.5 trillion possible values. Even at 200 new URLs per second for 10 years (about 63 billion URLs), you would use less than 2% of the available code space.
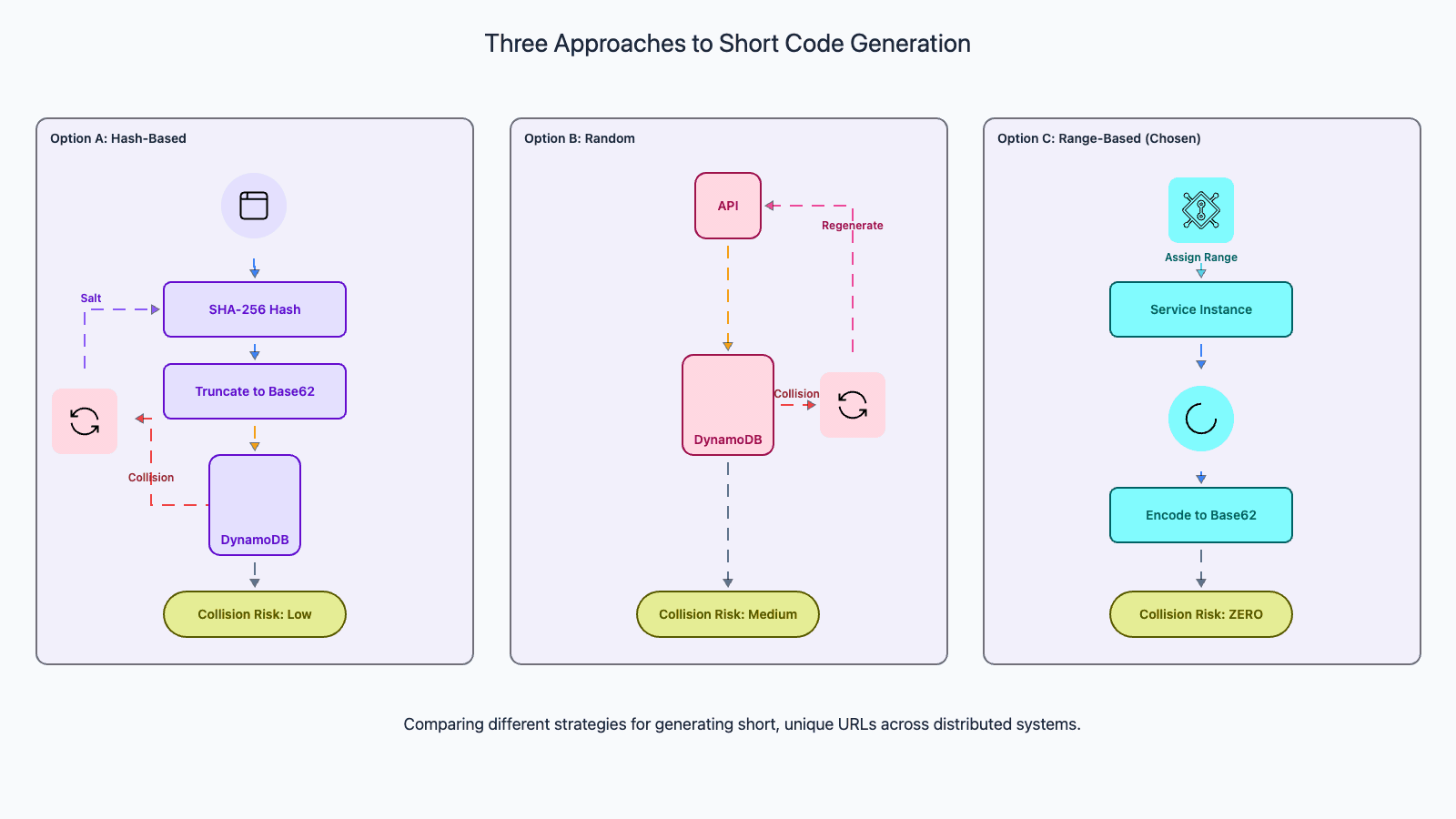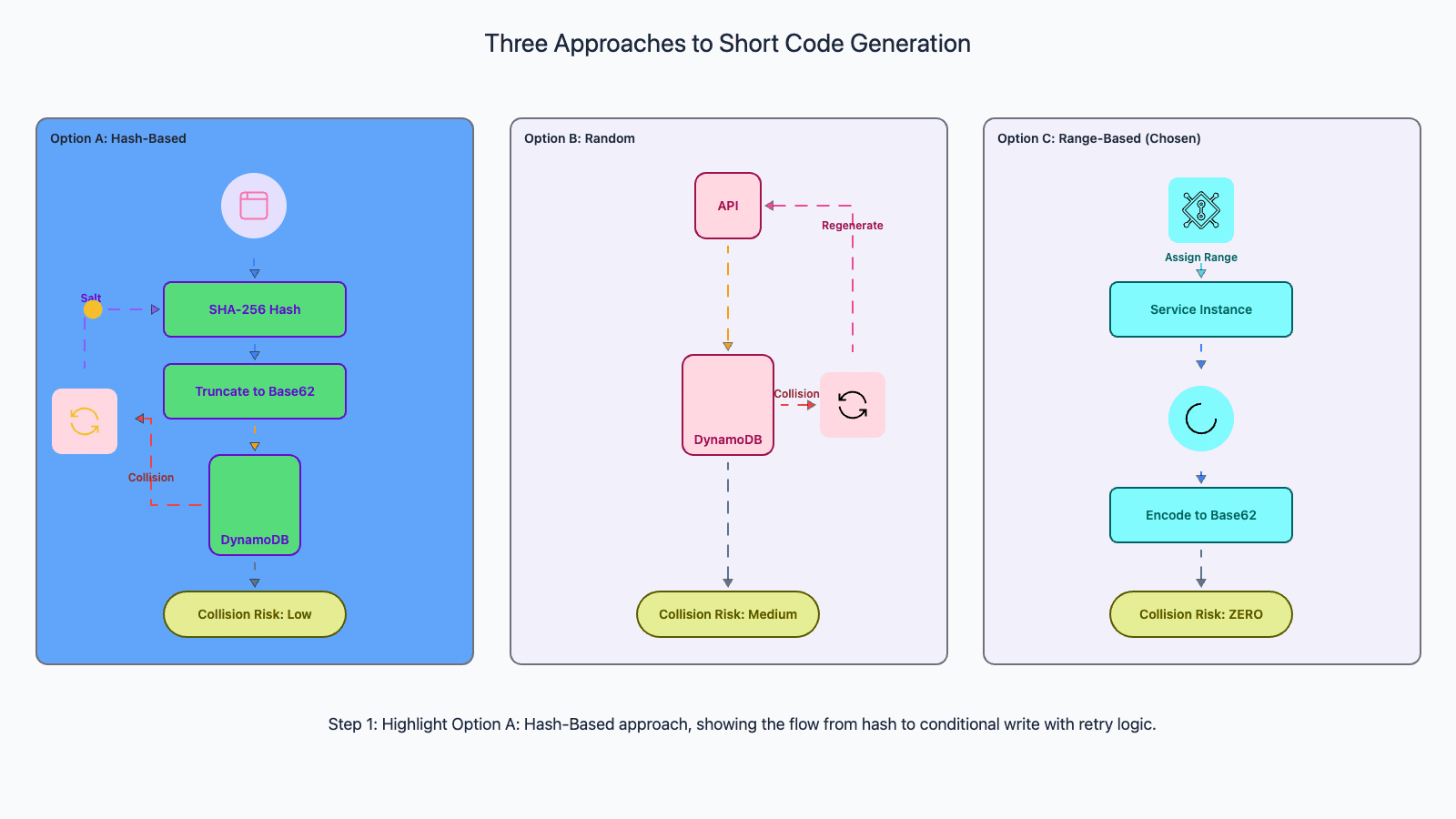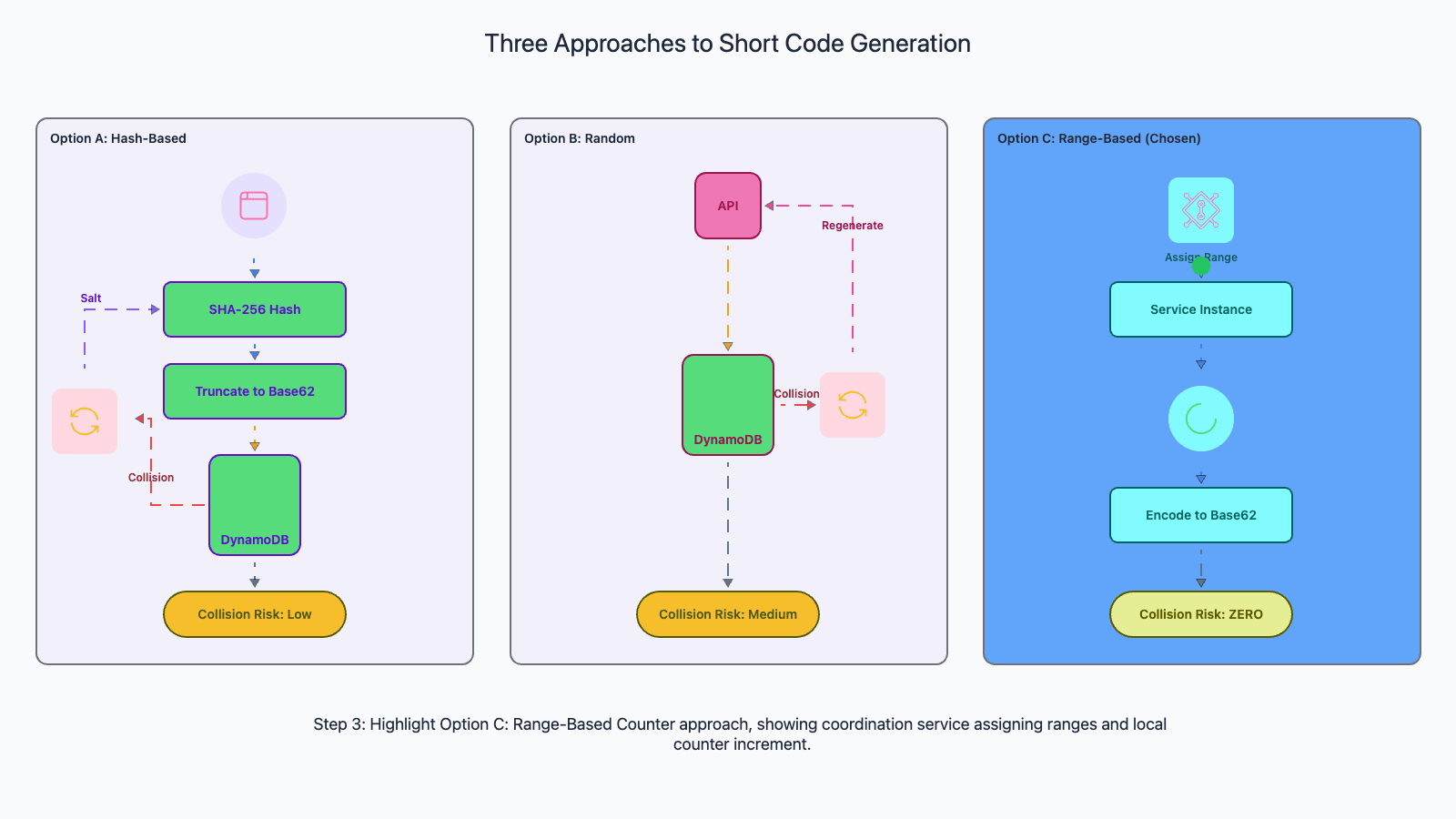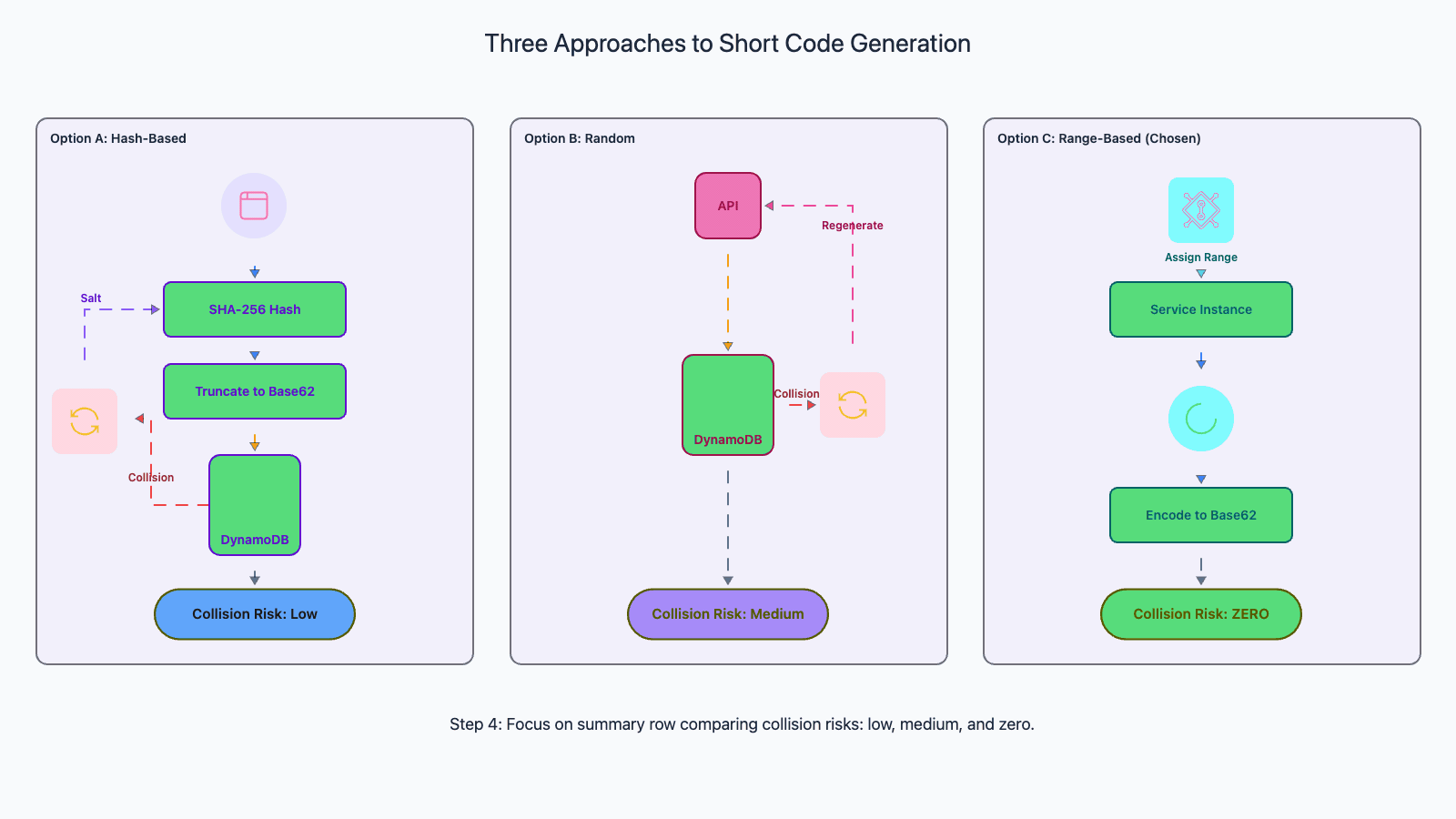
Approach 1: Hash then truncate. Hash the long URL using MD5 or SHA-256, then take the first 7 characters of the Base62-encoded hash. This is deterministic: the same long URL always produces the same short code, which provides natural deduplication. The problem: truncating a hash dramatically increases collision probability due to the birthday paradox. With 7 characters (3.5 trillion values), the probability of at least one collision reaches 50% at roughly 2 million entries.
Approach 2: Random generation. Generate a random 7-character Base62 string for each URL. This provides excellent distribution across the code space and avoids the truncation problem. The trade-off: two submissions of the same long URL produce different short codes, so you need a separate deduplication mechanism (the longUrl GSI). Collision probability is lower than truncated hashes because the full 7-character space is utilized uniformly.
Approach 3: Range-based counter (chosen approach). A coordination service (ZooKeeper or DynamoDB itself) pre-allocates large ranges of sequential IDs to each application server. Server A gets 1 to 1,000,000. Server B gets 1,000,001 to 2,000,000. Each server generates sequential IDs within its range and Base62-encodes them. Zero collision probability within a range. When a range is exhausted, the server requests a new one. This is the approach used in our write flow because it guarantees code uniqueness at generation time, making the async queue-based write pattern safe. The trade-off: requires a coordination service, and sequential IDs are somewhat predictable (mitigated by shuffling or salting the Base62 encoding).
 Short Code Generation: Hash vs Random vs Range-Based Counter
Short Code Generation: Hash vs Random vs Range-Based Counter
Collision Handling with Conditional Writes
Even with range-based allocation, the system uses conditional writes as a safety net (especially for custom aliases). DynamoDB conditional writes provide the safest mechanism.
A conditional write (PutItem with the condition that the partition key does not already exist) is atomic: it either succeeds or returns a ConditionalCheckFailedException in a single round-trip. There is no race condition window between checking and inserting because the check and the insert are the same operation.
With range-based allocation, collisions cannot occur because each server owns an exclusive ID range. For range-generated codes, every write succeeds on the first attempt. Custom aliases are the primary use case for conditional writes: two users might request the same alias simultaneously, so the Shortening Service performs a synchronous conditional write (bypassing the async queue) to confirm the alias is available before returning it to the client.
The alternative, a separate read-then-write pattern (first query to check if the code exists, then insert if it does not), has a fatal race condition. Two concurrent requests could both read "code does not exist" and both proceed to insert, with the second silently overwriting the first. Conditional writes eliminate this race entirely.
Caching Strategy
CDN (hot tier): Caches 302 redirect responses at edge locations. Best for viral and popular URLs that receive thousands of clicks per second. TTL-based expiration (e.g., 5 minutes) ensures updates eventually propagate. Limited storage, but the power-law access pattern means a small cache handles most traffic.
Redis (warm tier): In-datacenter cache using cluster mode with multiple shards. Stores millions of URL mappings in memory with LRU eviction. The cache-aside pattern means URLs are only loaded into Redis when someone actually clicks them, ensuring cache space is used for URLs people are actively visiting.
Why cache-aside over write-through: most newly created URLs are never accessed or accessed rarely. Write-through caching would fill Redis with millions of cold entries that nobody clicks, wasting memory. Cache-aside only populates the cache with URLs that generate actual traffic, maximizing the cache hit rate for a given memory budget.
Cache invalidation: When a URL mapping is updated (e.g., destination changed) or deleted, the system must invalidate the corresponding cache entries in both Redis and CDN. For Redis, delete the key directly. For CDN, use cache invalidation APIs (e.g., CloudFront invalidation) or rely on the short CDN TTL (5 minutes) for eventual consistency. In practice, the CDN TTL approach is simpler and the brief staleness window is acceptable for most use cases.
Partitioning
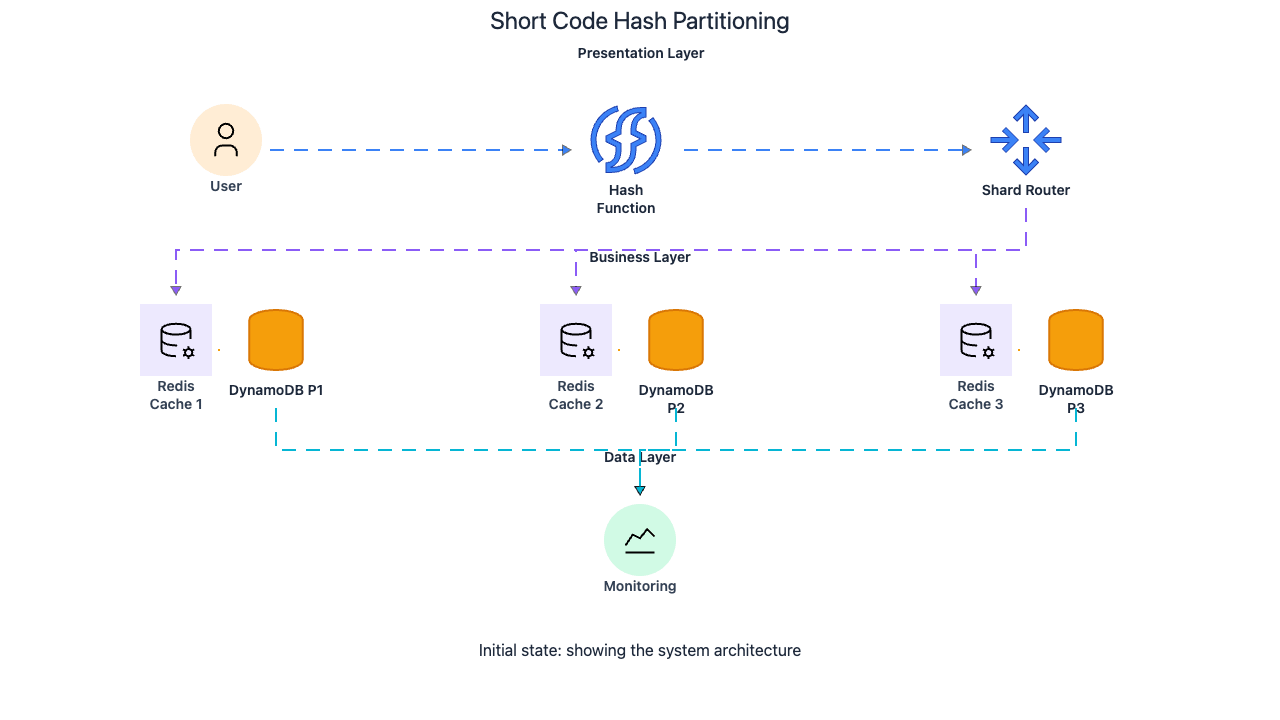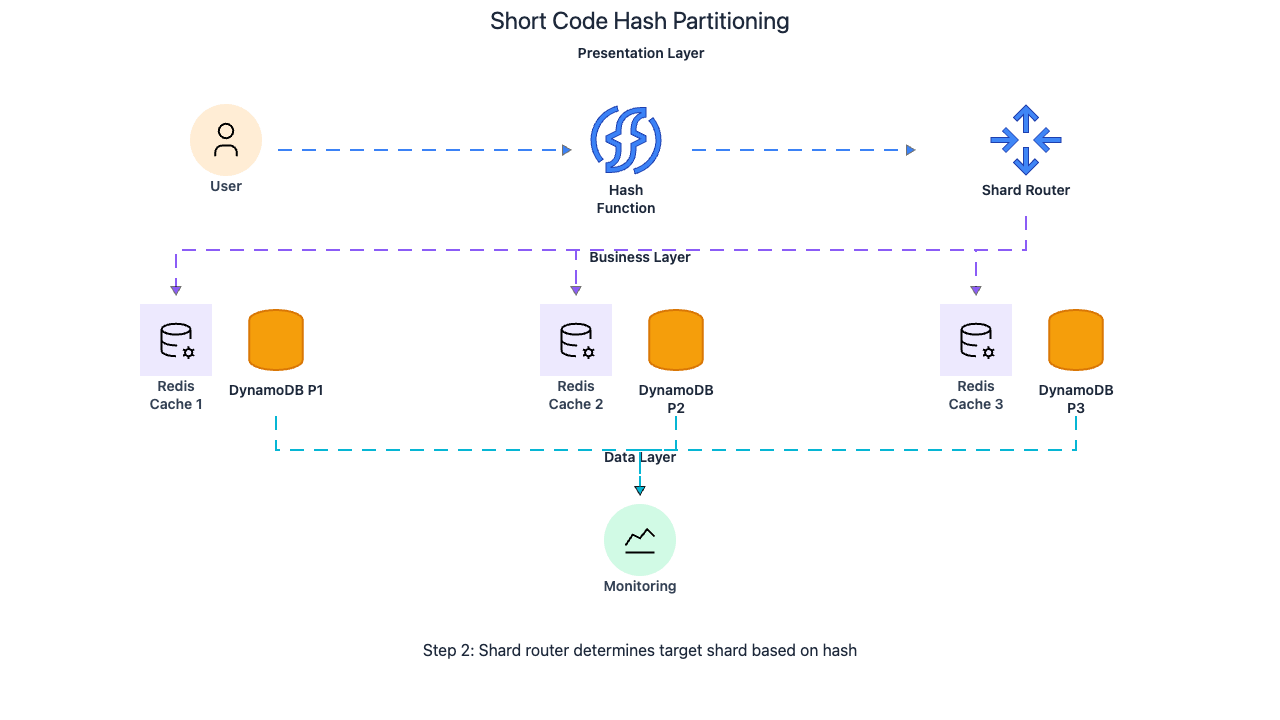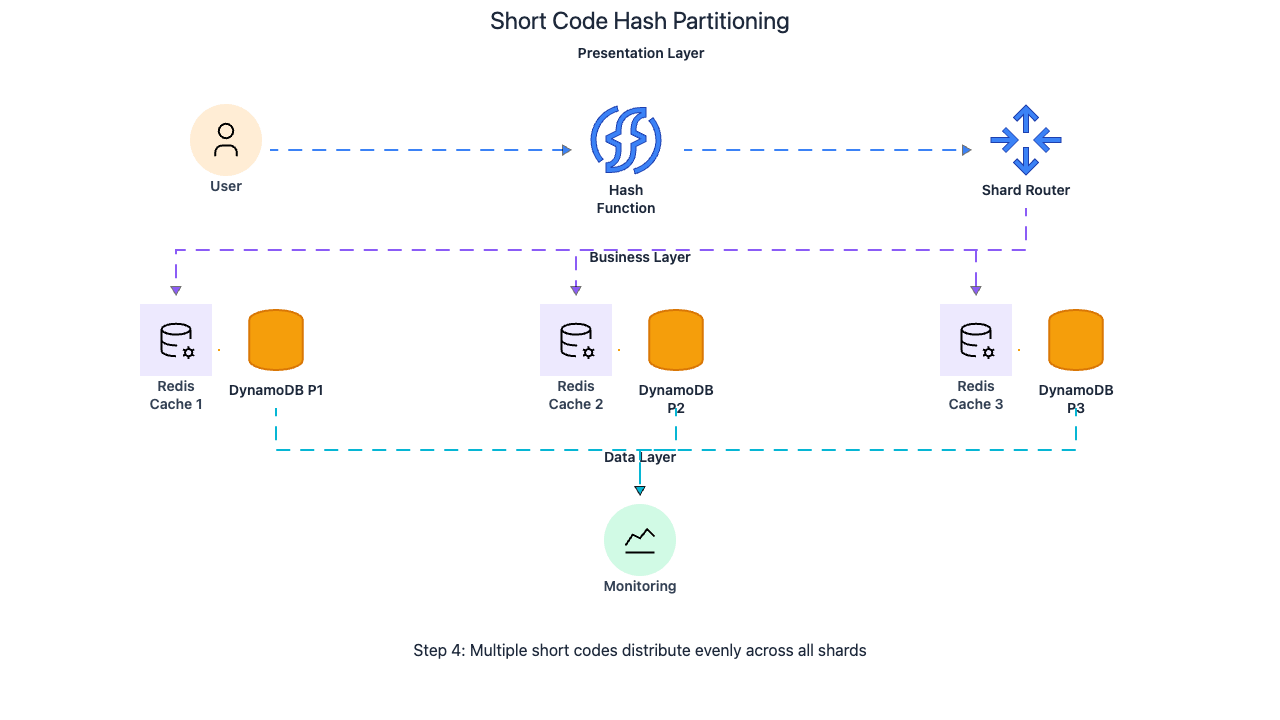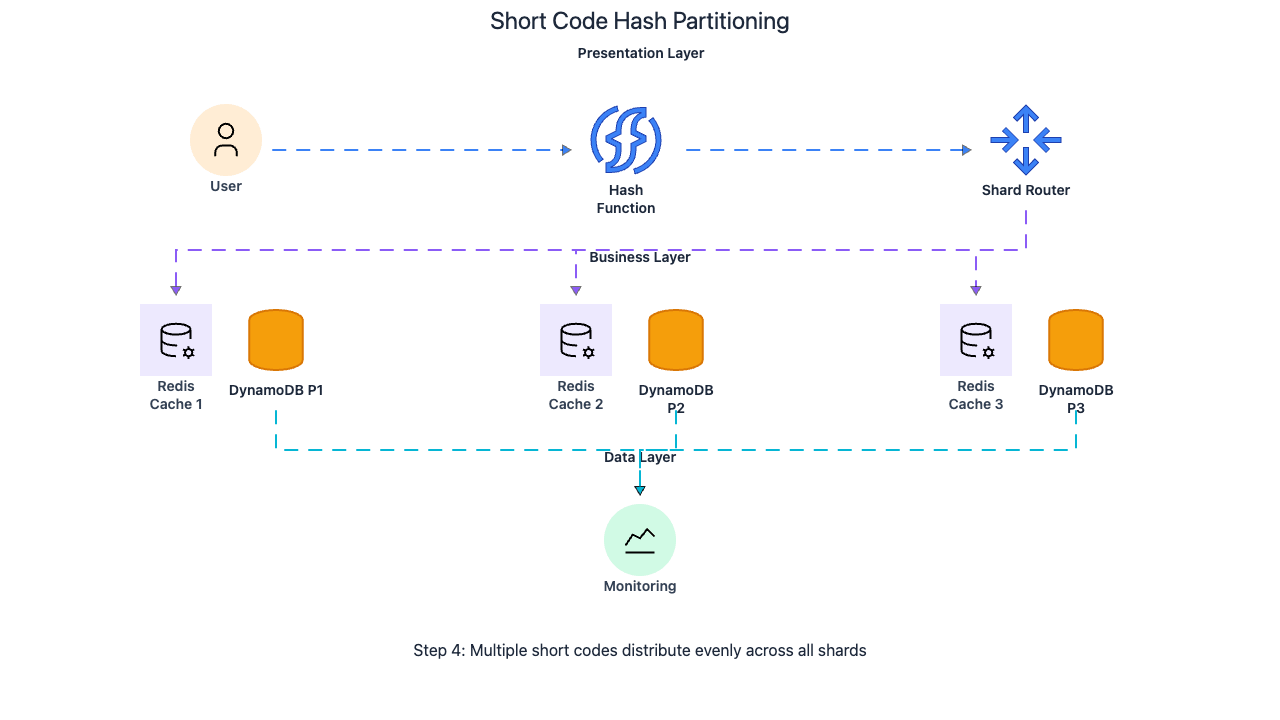 Partitioning: Shard by Short Code (Redis + DB Aligned)
Partitioning: Shard by Short Code (Redis + DB Aligned)
Both Redis and DynamoDB partition by the short code hash. This alignment means a single redirect lookup hits exactly one Redis shard and (on cache miss) exactly one DynamoDB partition. No fan-out reads across multiple shards.
Short codes distribute evenly across partitions because DynamoDB and Redis hash the code internally. Whether the code is generated from a range-based counter or randomly, the partition-level hash function distributes keys uniformly. Unlike user IDs (which can skew if one user creates millions of URLs) or long URLs (which vary wildly in length and distribution), short codes are fixed-length and drawn from a large space, so they hash evenly.
The short code is the ideal partition key because it is the primary lookup key (every redirect uses it), it is drawn from a large uniform space (even distribution after hashing), and it is fixed-length (consistent hashing behavior).
Why not partition by long URL or user ID? Long URLs vary wildly in length and structure: some domains (youtube.com, twitter.com) would concentrate on a few partitions while others have very few entries. User ID partitioning creates hotspots when a single power user generates millions of URLs. Short codes avoid both problems because they are drawn from a large, evenly distributed code space.
API design
Create Short URL
POST /api/v1/urls
Request body:
- longUrl (required): The destination URL to shorten
- customAlias (optional): A user-chosen short code instead of a system-generated one
- expiresAt (optional): ISO 8601 timestamp for when the link should stop working
Response (201 Created):
- shortCode: The generated or custom short code (e.g., abc123)
- shortUrl: The full short URL (e.g., https://tinyurl.com/abc123)
- longUrl: Echo of the original URL for confirmation
- createdAt: Timestamp of creation
- expiresAt: Expiration timestamp, if set
Authentication: API key in the Authorization header. Every write request must be associated with a registered account for rate limiting and abuse tracking.
Rate limit: 100 URLs per hour per API key for free tier. Higher limits for paid accounts. Returns 429 (Too Many Requests) when exceeded with a Retry-After header indicating when the client can try again.
Validation: The server should validate that the longUrl is a well-formed URL with a supported scheme (http or https). Reject URLs with unsupported schemes (javascript:, data:, ftp:) to prevent abuse. Optionally, check that the URL is reachable with a HEAD request, though this adds latency and is better done asynchronously.
Redirect
GET /shortCode
Returns a 302 (Found) response with the Location header set to the original long URL. The browser follows the redirect automatically. No authentication required. Anyone with the short URL can follow it. This is intentional. Short URLs are shared publicly and must work for everyone who clicks them.
If the short code does not exist or has expired, returns 404 (Not Found) with a JSON body explaining the error. For expired links, include a message indicating the link has expired rather than simply saying "not found." This helps users understand what happened and reduces confusion.
For SEO and social media compatibility, the redirect response should also include standard headers: Cache-Control to control CDN behavior, and optionally X-Robots-Tag to tell search engines whether to index the short URL or the destination URL.
Database design
Schema
- shortCode (partition key): The 7-character Base62 code. This is the primary lookup key for every redirect.
- longUrl: The original destination URL. Average length approximately 100 bytes.
- userId: The account that created this mapping. Links writes to specific users for management and billing.
- createdAt: Creation timestamp. Used for analytics and audit.
- expiresAt: Optional expiration timestamp. DynamoDB TTL uses this field to automatically delete expired items at no read/write cost.
Secondary Indices
Global Secondary Index on longUrl: This index enables duplicate detection. When a user submits a long URL that has already been shortened, the system can check the GSI in O(1) time and return the existing short code instead of creating a new one. This saves storage and avoids the confusion of multiple short codes pointing to the same destination.
Global Secondary Index on userId: This powers the user management dashboard. A user can query all URLs they have created to view click statistics, update destinations, or delete links. Without this index, listing a user's URLs would require a full table scan.